The training data includes many sets of input variables and a corresponding output variable. If you’re familiar with statistics, the inputs are often called independent variables and the output (classification) is called the dependent variable. Each set of corresponding independent variables and dependent variable is called an observation or example. An example of data from the pH.csv file included in your \ChaosHunter\Examples subdirectory appears below.
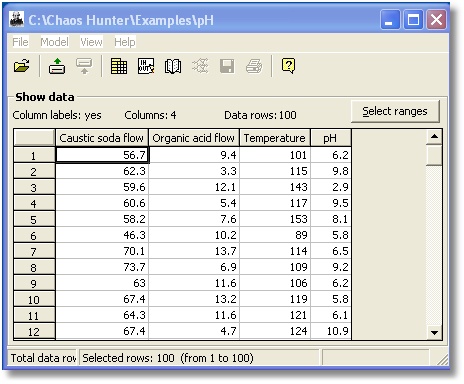
The examples in the training data should include a representative set of the problems likely to be encountered in the real world. For example, if you want to build a formula that predicts the pH value for a chemical process, you would consider inputs such as the amount of caustic soda flow and the amount of organic acid flow. You would need to include historical examples for all times of the year so you could account for seasonal variations (perhaps including a year or two of historical data). If you want to create a formula for predicting price change in stocks, you need to include historical examples of markets when the price went up, when it went down, and when it stayed the same. If historical information is not available, a subject matter expert could create training examples.
Warning: A formula developed by ChaosHunter (or any model) is only as good as the data with which you train it. If you do not provide inputs that effect the prediction, you cannot expect to get perfect formulas. If you do not show the model a wide variety of examples covering a range of input and output combinations, the formula may not later be able to accurately predict from some combinations of inputs.
Therefore, if your formula is not as accurate as you would like, investigate to see if you have provided the proper input variables, and an appropriate set of training examples.